
Granger causality
From Wikipedia, the free encyclopedia

The Granger causality test is a statistical hypothesis test for determining whether one time series is useful in forecasting another, first proposed in 1969.[1] Ordinarily,regressions reflect "mere" correlations, but Clive Granger argued that causality in economics could be tested for by measuring the ability to predict the future values of a time series using prior values of another time series. Since the question of "true causality" is deeply philosophical, and because of the post hoc ergo propter hoc fallacy of assuming that one thing preceding another can be used as a proof of causation, econometricians assert that the Granger test finds only "predictive causality".[2]
A time series X is said to Granger-cause Y if it can be shown, usually through a series of t-tests and F-tests on lagged values of X (and with lagged values of Y also included), that those X values provide statistically significant information about future values of Y.
Granger also stressed that some studies using "Granger causality" testing in areas outside economics reached "ridiculous" conclusions. "Of course, many ridiculous papers appeared", he said in his Nobel Lecture, December 8, 2003.[3] However, it remains a popular method for causality analysis in time series due to its computational simplicity.[4][5] The original definition of Granger causality does not account for latent confounding effects and does not capture instantaneous and non-linear causal relationships, though several extensions have been proposed to address these issues.[4]
Contents
[hide]Intuition[edit]
We say that a variable X that evolves over time Granger causes another evolving variable Y if predictions of the value of Y based on its own past values and on the past values of X are better than predictions of Y based only on its own past values.
Underlying principles[edit]
- The cause happens prior to its effect.
- The cause has unique information about the future values of its effect.
Given these two assumptions about causality, Granger proposed to test the following hypothesis for identification of a causal effect of  on
on  :
:
on :![\mathbb{P}[Y(t+1) \in A|\mathcal{I}(t)] \neq \mathbb{P}[Y(t+1) \in A|\mathcal{I}_{-X}(t)]](https://upload.wikimedia.org/math/c/7/4/c74b3903c49d0d5c61fc4a29ed773f10.png)
where 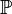 refers to probability,
refers to probability,  is an arbitrary non-empty set, and
is an arbitrary non-empty set, and 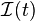 and
and 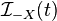 respectively denote the information available as of time
respectively denote the information available as of time  in the entire universe, and that in the modified universe in which is excluded. If the above hypothesis is accepted, we say that Granger causes .[4][6]
in the entire universe, and that in the modified universe in which is excluded. If the above hypothesis is accepted, we say that Granger causes .[4][6]
refers to probability, is an arbitrary non-empty set, and and respectively denote the information available as of time in the entire universe, and that in the modified universe in which is excluded. If the above hypothesis is accepted, we say that Granger causes .[4][6]Method[edit]
If a time series is a stationary process, the test is performed using the level values of two (or more) variables. If the variables are non-stationary, then the test is done using first (or higher) differences. The number of lags to be included is usually chosen using an information criterion, such as the Akaike information criterion or the Schwarz information criterion. Any particular lagged value of one of the variables is retained in the regression if (1) it is significant according to a t-test, and (2) it and the other lagged values of the variable jointly add explanatory power to the model according to an F-test. Then the null hypothesis of no Granger causality is not rejected if and only if no lagged values of an explanatory variable have been retained in the regression.
In practice it may be found that neither variable Granger-causes the other, or that each of the two variables Granger-causes the other.
Mathematical statement[edit]
Let y and x be stationary time series. To test the null hypothesis that x does not Granger-cause y, one first finds the proper lagged values of y to include in a univariate autoregression of y:
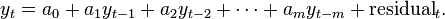
Next, the autoregression is augmented by including lagged values of x:

One retains in this regression all lagged values of x that are individually significant according to their t-statistics, provided that collectively they add explanatory power to the regression according to an F-test (whose null hypothesis is no explanatory power jointly added by the x's). In the notation of the above augmented regression, p is the shortest, and q is the longest, lag length for which the lagged value of x is significant.
The null hypothesis that x does not Granger-cause y is not rejected if and only if no lagged values of x are retained in the regression.
Multivariate analysis[edit]
Multivariate Granger causality analysis is usually performed by fitting a vector autoregressive model (VAR) to the time series. In particular, let  for
for  be a
be a  -dimensional multivariate time series. Granger causality is performed by fitting a VAR model with
-dimensional multivariate time series. Granger causality is performed by fitting a VAR model with  time lags as follows:
time lags as follows:
for be a -dimensional multivariate time series. Granger causality is performed by fitting a VAR model with time lags as follows:
where 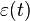 is a white Gaussian random vector. A time series
is a white Gaussian random vector. A time series 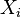 is called a Granger cause of another time series
is called a Granger cause of another time series 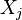 , if at least one of the elements
, if at least one of the elements  for
for  is significantly larger than zero (in absolute value).[7]
is significantly larger than zero (in absolute value).[7]
is a white Gaussian random vector. A time series is called a Granger cause of another time series , if at least one of the elements for is significantly larger than zero (in absolute value).[7]Limitations[edit]
As its name implies, Granger causality is not necessarily true causality. If both X and Y are driven by a common third process with different lags, one might still fail to reject the alternative hypothesis of Granger causality. Yet, manipulation of one of the variables would not change the other. Indeed, the Granger test is designed to handle pairs of variables, and may produce misleading results when the true relationship involves three or more variables. A similar test involving more variables can be applied with vector autoregression.
Extensions[edit]
A method for Granger causality has been developed that is not sensitive to deviations from the assumption that the error term is normally distributed.[8] This method is especially useful in financial economics since many financial variables are non-normally distributed.[9] Recently, asymmetric causality testing has been suggested in the literature in order to separate the causal impact of positive changes from the negative ones.[10]
Granger causality in neuroscience[edit]
A long held belief about neural function maintained that different areas of the brain were task specific; that the structural connectivity local to a certain area somehow dictated the function of that piece. Collecting work that has been performed over many years, there has been a move to a different, network-centric approach to describing information flow in the brain. Explanation of function is beginning to include the concept of networks existing at different levels and throughout different locations in the brain.[11] The behavior of these networks can be described by non-deterministic processes that are evolving through time. That is to say that given the same input stimulus, you will not get the same output from the network. The dynamics of these networks are governed by probabilities so we treat them as stochastic (random) processes so that we can capture these kinds of dynamics between different areas of the brain.
Different methods of obtaining some measure of information flow from the firing activities of a neuron and its surrounding ensemble have been explored in the past, but they are limited in the kinds of conclusions that can be drawn and provide little insight into the directional flow of information, its effect size, and how it can change with time.[12] Recently Granger causality has been applied to address some of these issues with great success.[13] Put plainly, one examines how to best predict the future of a neuron: using either the entire ensemble or the entire ensemble except a certain target neuron. If the prediction is made worse by excluding the target neuron, then we say it has a “g-causal” relationship with the current neuron.
Extensions to point process models[edit]
Previous Granger-causality methods could only operate on continuous-valued data so the analysis of neural spike train recordings involved transformations that ultimately altered the stochastic properties of the data, indirectly altering the validity of the conclusions that could be drawn from it. Recently however, a new general-purpose Granger-causality framework was proposed that could directly operate on any modality, including neural-spike trains.[12]
Neural spike train data can be modeled as a point-process. A temporal point process is a stochastic time-series of binary events that occurs in continuous time. It can only take on two values at each point in time, indicating whether or not an event has actually occurred. This type of binary-valued representation of information suits the activity of neural populations because a single neuron’s action potential has a typical waveform. In this way, what carries the actual information being output from a neuron is the occurrence of a “spike”, as well as the time between successive spikes. Using this approach one could abstract the flow of information in a neural-network to be simply the spiking times for each neuron through an observation period. A point-process can be represented either by the timing of the spikes themselves, the waiting times between spikes, using a counting process, or, if time is discretized enough to ensure that in each window only one event has the possibility of occurring, that is to say one time bin can only contain one event, as a set of 1s and 0s, very similar to binary.
One of the simplest types of neural-spiking models is the Poisson process. This however, is limited in that it is memory-less. It does not account for any spiking history when calculating the current probability of firing. Neurons, however, exhibit a fundamental (biophysical) history dependence by way of its relative and absolute refractory periods. To address this, a conditional intensity function is used to represent the probability of a neuron spiking,conditioned on its own history. The conditional intensity function expresses the instantaneous firing probability and implicitly defines a complete probability model for the point process. It defines a probability per unit time. So if this unit time is taken small enough to ensure that only one spike could occur in that time window, then our conditional intensity function completely specifies the probability that a given neuron will fire in a certain time.
See instead[edit]
- Transfer entropy
- Convergent cross mapping, another technique for testing for causality between dynamic variables





No comments :
Post a Comment
Note: only a member of this blog may post a comment.